
Architecture
The GEC 2050 heritage suggested a register-to-memory architecture, in which every micro-cycle will run one DRAM cycle. This set the speed of the machine, and logically pointed me toward a very close memory/CPU coupling, where the main internal CPU clocks are so timed as to serve also as the Precharge & Write memory clocks (1st-generation DRAMs did not use multiplexed addresses: there are no RAS/CAS strobes.) Those DRAMs were 600nsec cycle, but my rather inefficient design ran 1.6usec per read/modify/write cycle. The idea of using an 8-bit bus, with multi-precision arithmetic done by auto-indexing memory-address registers was borrowed from the 2050 (it was not novel to that, either). What I believe was my innovation was to do these multiple cycles not by loops in microcode, but by arranging that any microcode state (aka "box") could be repeated as needed. This vastly reduces the amount of microcode required. In the event, the entire microcode (including front-panel monitor functions) fitted in two bipolar 32 x 8 bit PROMs.
Construction
Simplex was hand-wired on 4 sheets of stripboard, approximately 150mm square. Each board had a standard load of 36 14/16 pin DIPs, with larger packages assigned more than one cell. The illustration shows the "Mill" card, which implemented the main data paths.The boards were fitted in a backplane, parallel to the front panel. The front card carried the monitoring functions, with the display LEDs on a sub-board fitted to it.
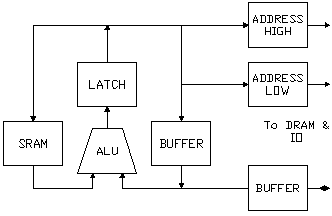
Organisation
All the machine registers (except C) are in the SRAM at the left of the block diagram. "LATCH" is the "anti-race latch", needed as the SRAM was not edge-triggered: it did not do read-modify-writes.The Address High & Address Low registers are chained as a 16-bit down-counter, enabling memory addresses to auto-decrement (recall, Simplex is big-endian) during multi-byte operations. The DRAM refresh counter (not shown) multiplexed with the outputs of the low address counter.
| Symbol | Function | Length |
| A | Accumulator | 1..8 bytes |
| X1 | Address base | 2 bytes |
| X2 | Address base | 2 bytes |
| X3 | Address base | 2 bytes |
| S | Instruction counter | 2 bytes |
| C | Condition codes/flags | 8 bits |
Registers
All registers are duplicated for interrupt & base level working. Memory can be addressed by a positive offset (0..255) from any of X1, X2, X3 or S.| Operation | 4 bits |
| Index register | 2 bits |
| Operand register | 2 bits |
Instruction Format
The 8 instruction bits are broken (in most instructions) into 3 fields as shown. The first operand is selected by the "operand register" bits, as A, X1, X2, or X3. The second operand is addressed in memory, by zero-padding the content of "LATCH" (the address offset), and adding the content of the "index register" S, X1, X2, or X3. As before, this addresses the highest (least-significant) addressed byte of the operand. As the operation proceeds, both the memory and SRAM address registers auto-decrement.Relative jumps are executed in the same way, by taking an address forward or back relative to S, and storing that address in S.
For all registers except A, the data length is fixed at 2 bytes. A "length" register can be loaded, to define the length of A at anything from 1 to 8 bytes. Of course, this value simply defines the repeat count for operations involving A. The length value remains set until explicitly changed again.
 Back to Home Page
Back to Home Page